Emission Management → Data Inventory
Written By CarbonX Registry
Last updated 9 months ago
The Data Inventory module serves as the central data processing hub of the CarbonX platform, bridging the transition between Data Entry and GHG Calculation. It consolidates, validates, and structures all uploaded or entered data, ensuring accuracy and transparency before emissions are formally computed.
This workspace is where sustainability teams, auditors, and data coordinators perform data verification, AI-assisted matching, and final confirmation of emission records.
It provides full visibility into the lifecycle of every data point — from raw extraction to final, verified calculation — supported by audit-ready tracking and intelligent feedback systems.
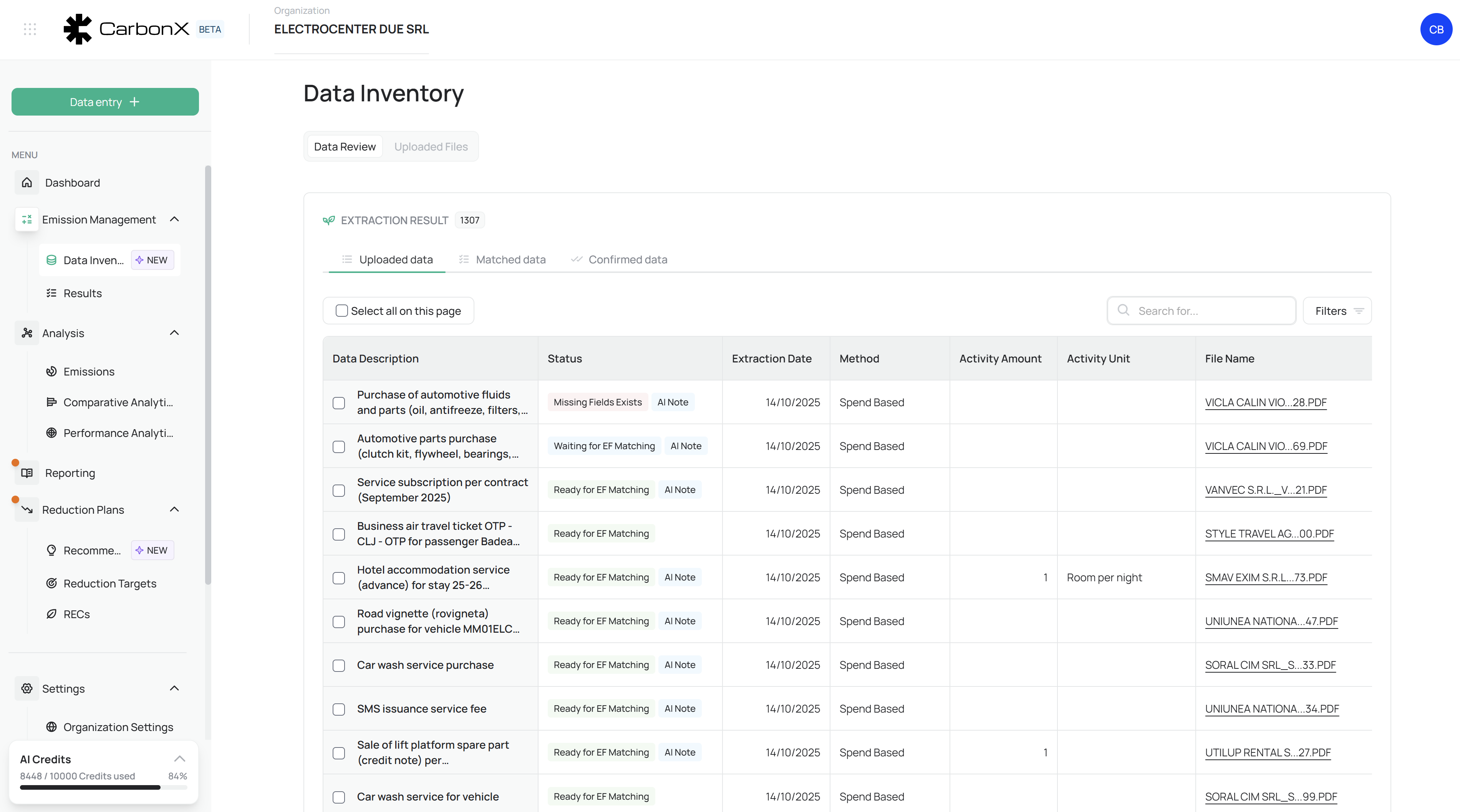
Image: Data Inventory interface showing the three-stage review pipeline (Uploaded → Matched → Confirmed), with AI Notes, proof document links, and calculation source visibility.
1. Purpose and Workflow Context
After data is entered via Custom Entry, Standard Upload, AI-powered Upload, or Integrations, it automatically flows into the Data Inventory.
Here, the platform performs three essential operations:
AI-based extraction – Interprets uploaded documents and identifies emission-related fields.
Emission factor mapping – Associates each record with verified activity-based emission factors (EFs).
Validation and confirmation – Finalizes records into auditable, calculation-ready datasets.
This sequential workflow transforms raw business data into structured, traceable carbon metrics compliant with international GHG accounting standards.
2. Main Interface Structure
The Data Inventory is organized into two primary tabs that support review and traceability:
A. Data Review Tab
This is the analytical heart of the module, presenting a live view of all processed emission records sorted into three validation stages:
Uploaded Data – Raw extracted information directly imported from uploaded files or manual entries. Each record displays validation tags like “Missing Fields Exists” or “Waiting for EF Matching” to indicate processing progress.
Matched Data – Entries that have been successfully paired with corresponding Emission Factors (EF Matched) through CarbonX’s AI model or user confirmation. The data now includes computed CO₂e estimates based on the factor applied.
Confirmed Data – Fully validated and approved entries that have passed AI verification or human review. These are locked for editing and automatically included in subsequent reporting and calculation processes.
Each record row displays columns for Activity Name, Facility, Scope, Emission Factor, Source File, Validation Status, and Reviewer.
B. Uploaded Files Tab
The second tab provides a chronological archive of all uploaded files and their extraction outcomes.
It helps users manage file-based traceability and review system-generated logs for:
File Type (PDF, Excel, CSV, etc.)
Uploader Identity and Timestamp
Extraction Status (Completed, In Progress, Failed)
Detected Entries Count
AI Processing Summary
This tab simplifies audit preparation by maintaining a full history of document uploads, transformations, and data lineage.
3. Data Review Workflow
The review process follows a clear, stage-based pipeline, enabling teams to monitor data maturity in real time.
A. Uploaded Data
Represents the raw, unprocessed dataset imported from uploads or manual entry.
The platform identifies incomplete fields, inconsistent units, or formatting errors.
Typical system flags include:
Missing Fields Exists – Required metadata or activity value is incomplete.
Waiting for EF Matching – Data has been captured but not yet mapped to an emission factor.
At this stage, users may manually edit values or re-upload supporting documentation to address flagged issues.
B. Matched Data
The AI Matching Engine links each valid activity record with the most appropriate Emission Factor (EF) from verified databases.
Users can review each suggestion, adjust the factor manually, or confirm the AI’s selection.
The interface also displays source tracking, showing whether the record originated from a Smart Upload, Manual Entry, or Integration Feed.
Once approved, the emission factor association triggers automatic emission calculations in tCO₂e units.
C. Confirmed Data
These are finalized and auditable records, verified by the system or an authorized reviewer.
Confirmed entries cannot be overwritten but can be referenced in reporting or exported for audit purposes.
Data in this stage contributes directly to GHG footprint summaries, dashboards, and emission reduction analytics.
4. Functional Highlights
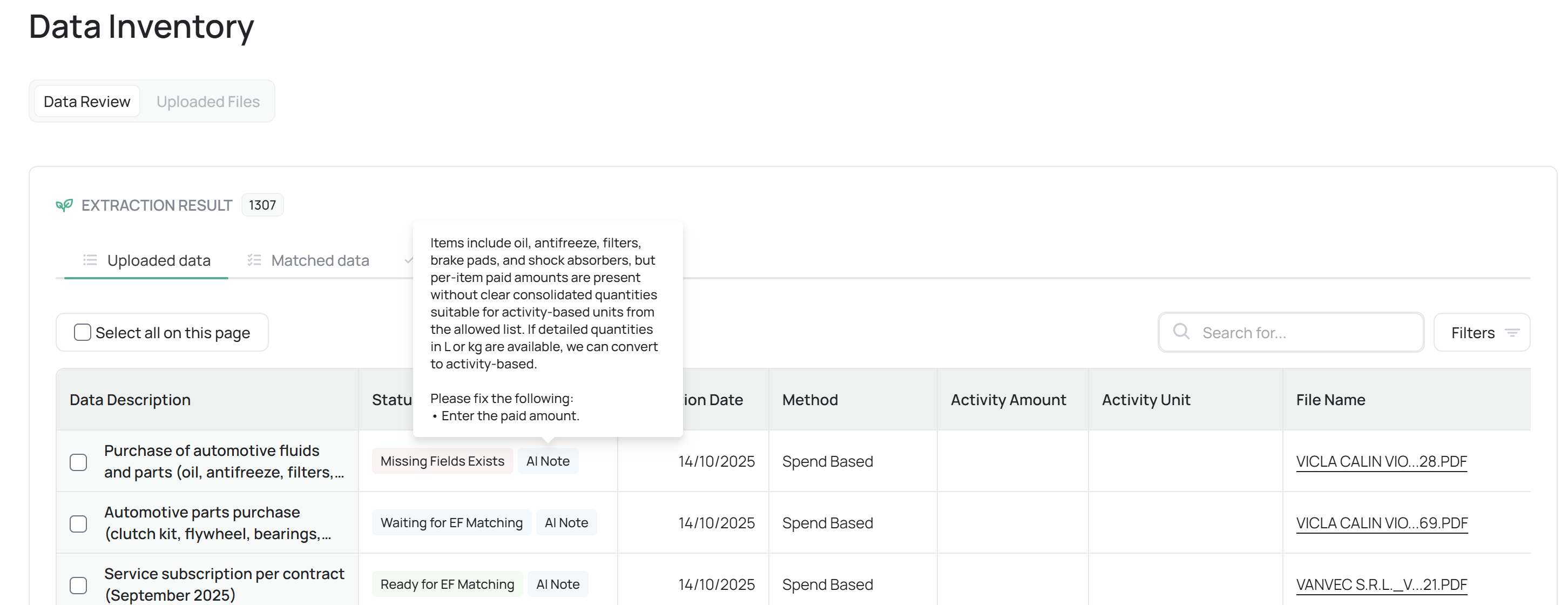
AI Notes
Each record may include contextual AI Notes — brief annotations automatically generated by the platform’s data intelligence engine.
These provide insights such as:
Data completeness evaluations
Matching confidence levels (e.g., “EF match confidence: 96%”)
Suggested corrections or clarifications
This feature minimizes review time by highlighting areas requiring human validation.
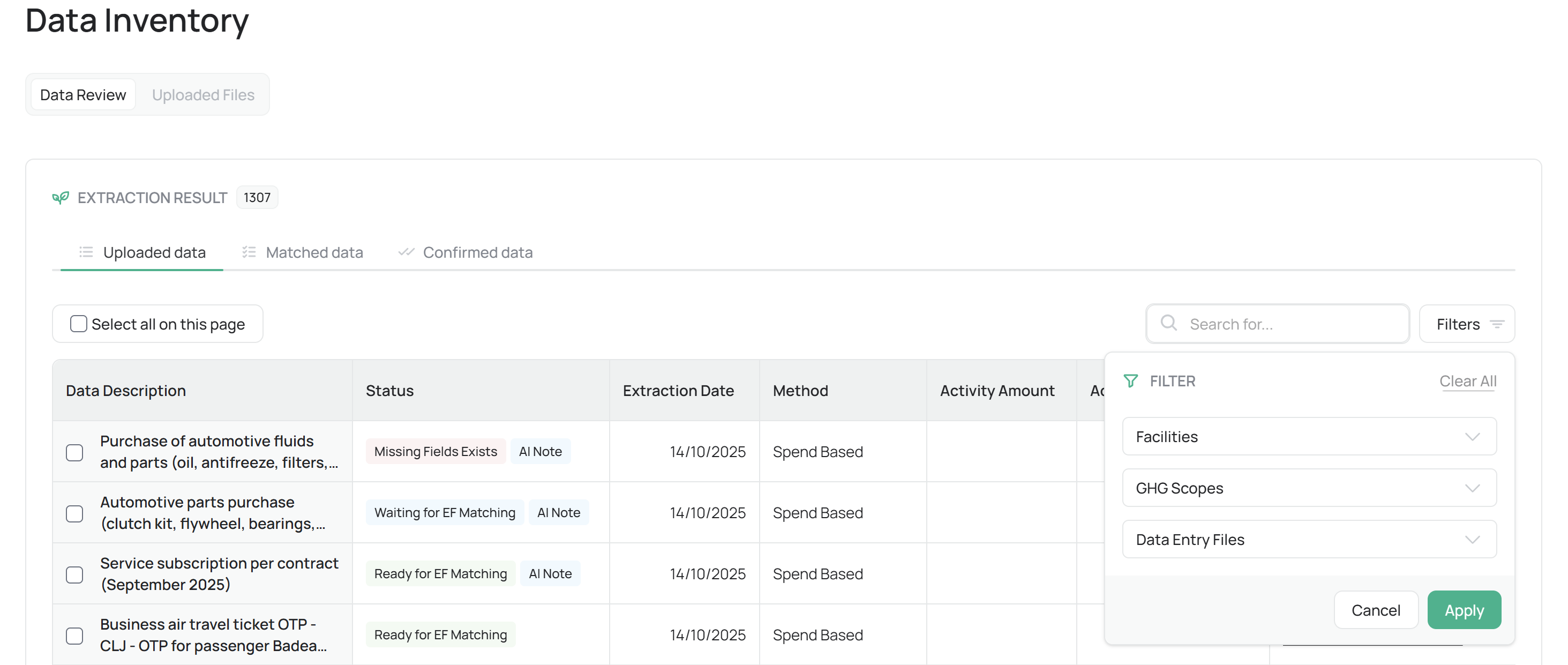
Filters & Search Tools
The Data Inventory includes advanced filters for sorting or searching records by:
Activity Name / Source Category
Facility or Scope
Upload Status (Uploaded, Matched, Confirmed)
Date Range or Uploader
These tools allow users to quickly locate entries across extensive datasets.
Proof Linking
A key transparency feature, Proof Linking enables direct cross-referencing between a calculated emission record and its originating uploaded document.
This audit trace ensures that every emission value has a verified evidence source, bolstering credibility for audits and compliance reviews.
Calculation Source Visibility
Each emission record is tagged with its origin type, displaying whether the result originated from:
Smart Upload (AI extraction and automatic matching)
Manual Entry (human-entered record)
Integration (data imported via external system)
This transparency helps reviewers differentiate between automated and manually curated data.
5. Typical Workflow Example
Upload or enter data using any Data Entry method.
Review uploaded records under Uploaded Data, correcting incomplete or inconsistent fields.
Validate matches in Matched Data, confirming or adjusting emission factors.
Approve finalized records in Confirmed Data, which automatically sync to dashboards and reporting modules.
Reference source documents in Uploaded Files for audit trails or verification checks.
This logical progression ensures end-to-end data traceability and quality assurance.
6. Best Practices
Regularly review AI Notes to quickly resolve data issues.
Always confirm emission factors manually for outlier values or custom activities.
Utilize Proof Linking before submitting reports for external verification.
Filter by status or facility to manage large, multi-site datasets efficiently.
Revisit the Uploaded Files tab monthly to ensure no pending extractions remain unreviewed.